공공 데이터로 재밌는거 만들어 볼만한게 있을까 고민하던 중 시작한 개인 프로젝트.
공부도 할 겸 만들어 보고 싶다 생각해서 진행했지만 흐지부지 끝난 프로젝트가 두 개.
이번 프로젝트가 세번 째인데 제법 재미를 붙여서 하기도 했고
이번엔 진짜 오픈까지 해봐야겠다 마음 먹고 진행중인 프로젝트여서 진행 중 기록할만한 것 들을 짤막하게 남겨놨다가 까먹기 전 포스팅을 남기기 시작한다.
상황
MVP로 빠르게 만들어서 오픈 후 운영하며 고도화를 진행하는 것을 목표로 하고 있기 때문에 바로 테스트 DB에 데이터를 늘려가며 적재해 테스트를 하는 과정에 성능 개선의 필요성을 느껴 작업을 진행했고 그 과정에 테이블 파티션으로 성능을 개선해 문서로 본 포스팅을 작성한다.
현재까지 상황은 이러하다.
- 공공 데이터 포털에서 제공하는 API로 자체 DB에 데이터를 정제해 적재하는 Spring Batch job 개발
- 기본 조회 API 개발
- 핵심 기능에 사용되는 테이블에 테스트 데이터가 약 80만건 정도 들어가 있는 상황이고, 운영시 160만건 + @ 정도에 일정 기간마다 배치를 돌려 새 데이터를 적재할 예정.
이 과정에서 기본 조회 API가 1초가 넘게 걸리고, 특정 조건에서는 2초까지 늘어지는 상황이 발생했다.
고려한 해결책
1. 조회조건마다 인덱스를 추가한다.
A. 데이터량이 앞으로도 계속해서 쌓일 예정으로, 공공 데이터를 정제해서 사용하는 데이터로 임의의 update 트랜잭션이 발생하지는 않겠지만 주기적으로 수 만 ~ 수 십만건의 데이터가 insert되어 누적되는 구조라 공간을 너무 많이 차지하게 될 것으로 예상된다.
2. 조회 API 필수 파라미터 중 월에 해당하는 값이 존재하고, 데이터에 날짜값이 존재하므로 월별로 파티셔닝을 수행한다.
A1. MySQL에서 지원하는 파티션 최대 수는 8192로 월별로 파티셔닝을 수행하면 단순 계산으로도 약 682년치 파티션 사용 가능
A2. MySQL 정책상 8192를 지원한다는 뜻이다. 테이블의 각 파티션은 내부적으로 하위 테이블로 인식되고, 옵티마이저가 쿼리 실행 전 몇 개의 파티션을 봐야하는지 매번 계산하는 오버헤드가 발생해서 실제론 수백개 이하가 권장된다고 한다. 하지만 그정도면 월별로 파티셔닝을 했을 때 장기로 데이터를 보관해도 괜찮다는 판단이 들었고, 이후에 너무 오래되어 필요가 없어진 오래된 파티션과 데이터는 drop 하는 방식으로 대응할 수 있을거라 판단이 되었다.
A3. 다만 파티션을 추가하는 작업은 데이터가 insert 되기 전에 수행을 해주어야 해서 배치를 돌리기 전 수동으로 파티션을 추가해주어야 하는데, 이 부분은 미리 몇 달치의 파티션을 생성해두고 그 안에 자동화 스크립트를 짜서 cron을 걸어주기로 했다.
파티셔닝 작업
먼저 현재 데이터가 들어있는 테이블에 파티션을 걸 수는 없고 데이터를 유지한 채 파티션 구조로 재생성해야 한다.
MySQL은 파티션을 내부적으로 하나의 하위 테이블로 인식하기 때문에 여러 하위 테이블 구조로 다시 만들어야하기 때문이다.
파티션 테이블 작업 시 주의사항
- PK 에 파티션 키 포함 필수 → id만 PK면 안되고 파티션 키가 포함되어야 한다.
- 인덱스 추가 시에도 파티션 키가 들어가야 파티션 프루닝이 유효하므로 인덱스 추가시에 파티션 키를 함께 추가한다.
- 테이블 크기 클수록 ALTER 대신 새 테이블 추천
- FK 걸려있으면 파티션 추가 불가능
- DDL 실행 중엔 lock 발생하므로 트래픽이 있는 서비스라면 유지보수 시간대에 수행해야한다.
일단 인덱스를 새로 걸어주어야 하기도 하고, 파티셔닝을 하게 되면 파티션 키를 PK에 추가해주어야 하기 때문에
새 파티셔닝 테이블을 만들고 데이터를 모두 이관한 후 RENAME 하는 방식으로 작업을 진행했다.
1. 현재 애플리케이션 JPA 연관관계 관련 소스 수정
DB작업에 들어가기에 앞서 기존에 FK를 걸어두고, @JoinColumn을 지정해둔 Jpa Entity 소스와 Mapstruct 매퍼 인터페이스를 수정해주었다.
2. 파티션 테이블 생성
기존 테이블의 컬럼 정의는 그대로 유지한 채, 파티션을 아래 문법에 따라 걸어주었다.
CREATE TABLE table_name (
-- 컬럼 정의
)
PARTITION BY RANGE (파티션기준컬럼 or 표현식) (
PARTITION 파티션이름 VALUES LESS THAN (값),
PARTITION 파티션이름 VALUES LESS THAN (값),
...
)
그리고 아래 기준에 맞춰 작업을했다.
- id + 파티션 키를 복합키로 pk지정
- JPA에서는 id로만 식별자 가져간다. (@Id 어노테이션)
- DB에서는 복합 PK지만 JPA는 id 단독으로 논리적 식별자로 인식해도 문제없음.
3. 기존 테이블 FK 관계 제거
FK 확인 쿼리를 수행해 FK이름을 확인 한 후 ALTER로 기존 테이블에 걸려있는 FK를 DROP 해준다.
-- FK 확인
SELECT
CONSTRAINT_NAME,
COLUMN_NAME,
REFERENCED_TABLE_NAME,
REFERENCED_COLUMN_NAME
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE TABLE_SCHEMA = 'DB이름'
AND (
TABLE_NAME = '테이블이름'
OR
...
)
AND REFERENCED_TABLE_NAME IS NOT NULL;
-- FK 끊기
ALTER TABLE 테이블이름 DROP FOREIGN KEY FK이름;
...
4. 데이터 이관 및 테이블 RENAME
기존 테이블이름은 임의의 테이블 이름으로,
새로 생성한 파티션테이블 이름은 기존 테이블 이름으로 변경해준다.
-- 데이터 이관 -> RENAME
INSERT INTO 파티션테이블이름
SELECT * FROM 기존테이블이름;
RENAME TABLE 기존테이블이름 TO 기존테이블이름_old,
파티션테이블이름 TO 기존테이블이름;
테스트
테스트를 해보자.
현재 테스트데이터는 요정도,,
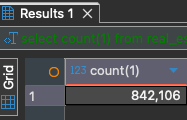
그리고 성능 개선 작업 진행 전 어느정도 걸렸는지 확인하면 이렇다.

물론 조건에 맞는 데이터가 없어 full scan이 발생한 것으로 보이는데 그렇다해도 너무 오래 걸린다.
위의 작업을 모두 수행하고 나니 아래와 같이 매우 빨라졌다.
